
{kind=link}
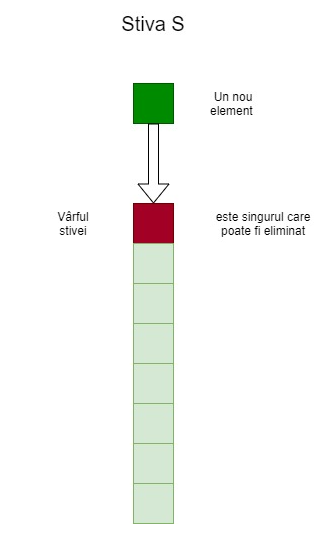
Analiza amortizată este o metodă de evaluare a eficienței algoritmilor care operează asupra unor structuri de date. De obicei analiza amortizată e aplicată în cazul listelor liniare, care sunt structuri de date ce pot reține mulțimi bine ordonate finite. Stiva este o astfel de structură, organizată după principiul Last In First Out (ultimul sosit, primul servit). Mai exact (ca și în cazul unei stive de farfurii) inserarea unui nou element se face totdeauna înaintea ultimului adăugat, iar singurul element care poate fi eliminat la un moment dat este cel mai recent adăugat.
În cadrul acestui articol vom urmări rezolvarea unor probleme de tip „Skyline”, în care ni se cere găsirea unei suprafețe dreptunghiulare de arie maximă formată prin alăturarea unor blocuri consecutive.
Aplicația 1
Vom începe cu o problemă pregătitoare, în care fiind dat un șir numeric ni se cere să răspundem rapid la întrebări de forma: „care este cel mai apropiat element mai mic strict decât cel aflat pe o poziție dată?”
După citirea elementelor șirului, pe care le vom păstra în vectorul x, strategia va fi aceea de a precalcula doi vectori, st și dr cu ajutorul unei stive numite chiar stiva și de a răspunde apoi offline la toate întrebările. Cei doi vectori vor corespunde celor două tipuri de întrebări: „care este cel mai apropiat element al vectorului mai mic ca x[i] situat în stânga, respectiv în dreapta acestuia?”
Mai exact, elementele celor doi vectori vor avea semnificația:
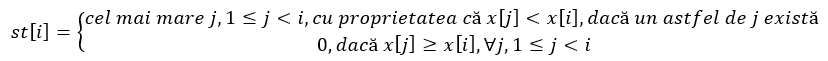
și respectiv
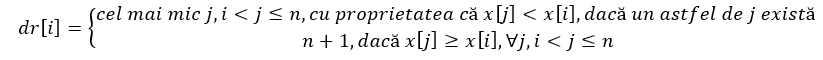
ceea ce va corespunde atât cerințelor problemei curente, cât și unei etape necesare pentru obținerea rezultatelor corespunzătoare următoarelor aplicații prezentate în cadrul articolului.
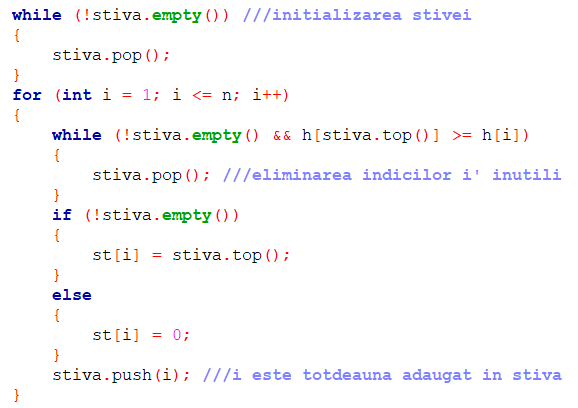
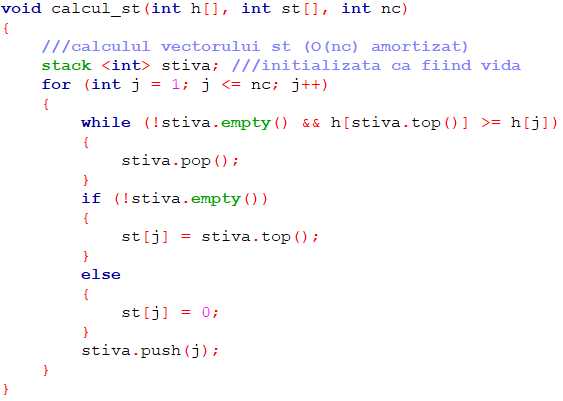
Pentru construcția vectorului st definit mai sus vom folosi următorul algoritm:

Subrutinele EMPTY(S), TOP(S), POP(S) și PUSH(S, i) corespund respectiv verificării dacă stiva e vidă, consultării elementului accesibil al acesteia, numit și vârful stivei (cel mai recent adăugat), eliminării vârfului și adăugării lui i la S. Fiecare dintre acestea are complexitatea O(1) (poate fi realizată cu un număr constant de operații elementare).
Se observă că pentru a calcula st[i] parcurgem vectorul de la stânga la dreapta și la fiecare pas i cuprins între 1 și n păstrăm în stivă doar acei indici i’ cu proprietatea că e posibil să existe j > i’ astfel încât st[j] = i’. În acest scop, la pasul i eliminăm din stivă acei indici i’ cu proprietatea că:
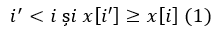
Pentru a verifica faptul că algoritmul e corect vom demonstra mai întâi prin inducție după i următorul rezultat:
Lema 1: Stiva construită conform algoritmului de mai sus are proprietatea că dacă i și j aparțin lui S și i se află pe un nivel inferior al acesteia (a fost adăugat înaintea lui j), atunci i < j și x[i] < x[j].
Demonstrație: Rezultatul este evident verificat după prima iterație, întrucât S va conține un singur element.
Presupunem că afirmația e adevărată înaintea pasului i și demonstrăm că relația se păstrează și după acesta. Întrucât elementele adăugate în S (linia 16) sunt parcurse crescător (linia 2) este clar că toate valorile din stivă sunt mai mici ca i. În plus instrucțiunile de la liniile 4-7 și ipoteza inductivă ne asigură că pentru orice j rămas în S înaintea instrucțiunii de la linia 16 avem x[j] < x[i]. Astfel adăugarea lui i în S păstrează proprietatea cerută. Deci lema e verificată.
În continuare ne vom concentra asupra elementelor eliminate din stivă la liniile 4-7 ale algoritmului.
Lema 2: Indicii i’ eliminați din stivă până la pasul i inclusiv al algoritmului de mai sus au proprietatea că oricare ar fi j > i avem certitudinea că st[j] este diferit de i’.
Demonstrație: După la pasul i indicele i’ verifică relația (1), atunci pentru orice j > i cu proprietatea că x[j] > x[i’], conform relației (1) și tranzitivității vom avea și x[j] > x[i] și cum i’ < i rezultă că st[j] nu poate fi i’ (nu avem certitudinea că pentru un astfel de j st[j] = i, dar după apariția lui i suntem siguri că st[j] nu este i’).
Cu alte cuvinte, am demonstrat că algoritmul de mai sus păstrează în S acei indici i’ pentru care e posbil să existe j > i cu proprietatea că st[j] = i’.
O observație interesantă (dar nu esențială pentru verificarea corectitudinii algorimtului) este că indicii păstrați în S după primii i pași pot apărea printre valorile st[j] cu j > i. Mai precis, dacă la pasul i un indice i’ aflat în stivă (deci cu proprietatea i’ < i) nu verifică relația (1), adică x[i’] < x[i] este posibil să existe j > i cu proprietatea că x[j] > x[i’] și totuși x[j] să nu fie mai mare și ca x[i]. Deci apariția lui i nu înseamnă că un astfel de i’ nu mai prezintă interes și prin urmare i’ trebuie păstrat în stivă.
În particular, la pasul i indiferent de valoarea lui x[i] acesta trebuie adăugat la S (linia 16). Într-adevăr, dacă x[i+1] = 1+x[i], atunci st[i+1] = i.
Rămâne să arătăm (cu ajutorul celor două leme) că algoritmul construiește corect vectorul st.
La pasul i, în urma executării instrucțiunilor liniilor 4-7 distingem două situații posibile.
- În cazul în care stiva a rămas nevidă elementele acesteia sunt indici mai mici ca i, cu valori în vectorul x mai mici de asemenea ca x[i] (lema 1). Acei indici care au fost eliminați din S nu pot fi st[i] conform lemei 2. În plus, din lema 1 rezultă că indicele din vârful stivei reprezintă cel mai mare indice mai mic decât i pe care se află un element strict mai mic decât x[i]. Deci atribuirea de la linia 10 este justificată.
- Dacă stiva a devenit vidă în urma executării instrucțiunilor de la liniile 4-7 înseamnă că vectorul x nu are în stânga poziției i elemente mai mici ca i și prin urmare st[i] = 0.
În ceea ce privește complexitatea algoritmului, se poate observa că acesta este un caz particular al uneia dintre problemele clasice urmărite în cadrul articolului general dedicat analizei amortizate.
Mai precis, algoritmul de mai sus se încadrează în tiparul operațiilor efectuate asupra stivei:

Cu operațiile executate la liniile 4-7 corespunzând subrutinei MULTIPOP:

Cum operațiile asupra stivei din algoritmul general au complexitatea O(n) amortizat, rezultă că și algoritmul din articolul prezent este unul liniar.
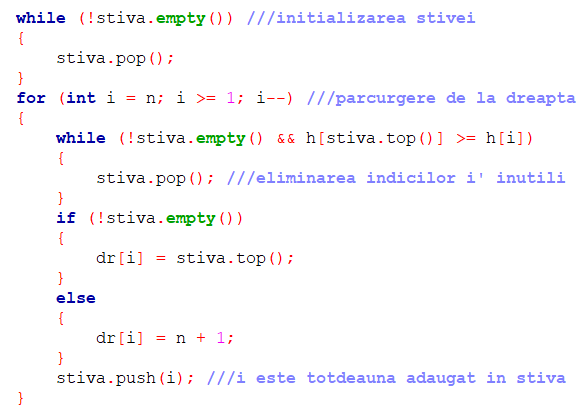
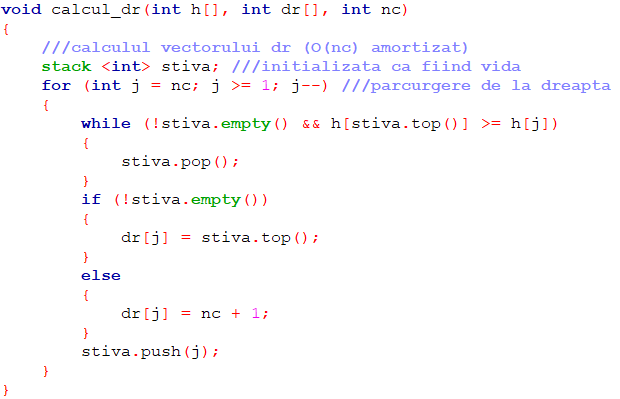
Pentru construcția vectorului dr vom folosi un algoritm similar:

Singurele diferențe apar la liniile 2, 10 și 14. Având în vedere semnificația vectorului dr, este necesar ca de data aceasta indicii să fie parcurși descrescător.
Prezentăm mai jos implementarea în limbajul C++ a algoritmilor pentru construcția vectorilor st și dr.
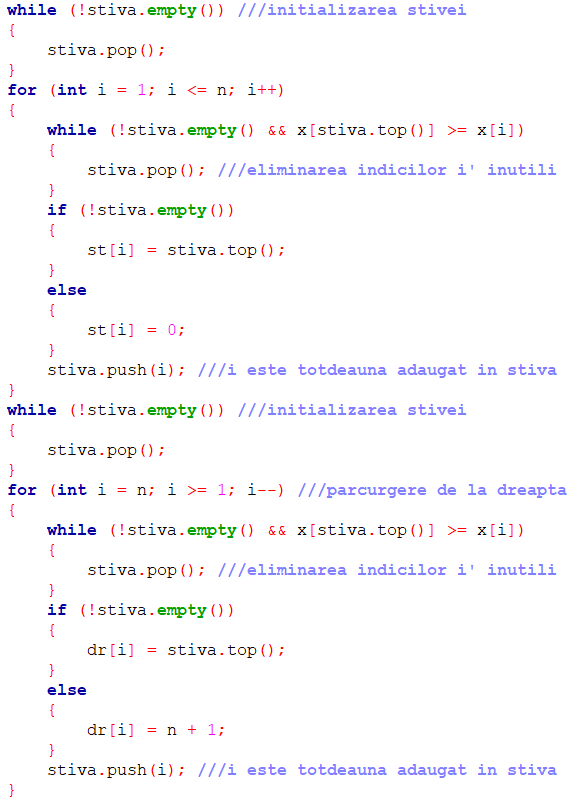
Am folosit obiectul de tip stack <int> denumit sugestiv „stiva” și metodele de bază empty, top, pop și push.
Aplicația 2
Următoarea problemă prezentată este probabil cea mai cunoscută, fiind totodată și cea care dă numele categoriei, „Skyline”.
Avem la dispoziție un set de blocuri de diverse lățimi și înălțimi și ni se cere aria maximă pe care o poate avea un dreptunghi inclus în figura geometrică obținută prin reunirea tuturor blocurilor date.
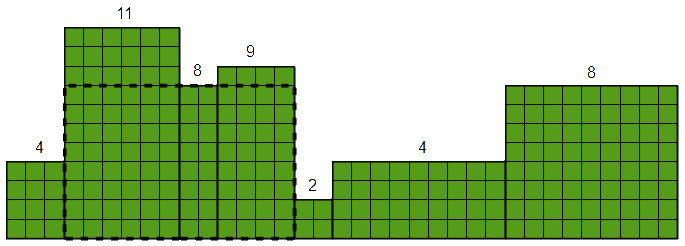
Probabil cel mai interesant aspect al problemei este acelă că o soluție eficientă este relativ dificil de descoperit. Pornind însă de la problema (pregătitoare) anterioară și făcând câteva observații un algoritm de complexitate O(n) amortizat va deveni mult mai ușor de intuit.
Observația 1 Dreptunghiul de arie maximă se obține dintr-o submulțime de blocuri aflate pe poziții consecutive în șirul dat.
O astfel de submulțime de blocuri o vom denumi în continuare secvență.
Afirmația e evident adevărată întrucât cerința problemei ne obligă să luăm doar blocuri consecutive în șir, iar dacă vrem să obținem o arie cât mai mare nu avem de ce să luăm doar o parte dintr-un bloc (o parte din primul sau ultimul).
Observația 2 Fiecare submulțime de blocuri consecutive este unic determinată de alegerea primului (celui mai din stânga) și ultimului (celui mai din dreapta) bloc component. Rezultă imediat că numărul de secvențe de blocuri este n(n+1)/2 pentru un șir format din n blocuri.
Într-adevăr avem o secvență în care cel mai din dreapta bloc este primul din șir, două secvențe în care cel mai din dreapta bloc este cel de-al doilea, … n secvențe în care cel mai din dreapta bloc este al n-lea.
Pornind de la acest rezultat am putea construi un algoritm de rezolvare pătratic, dar vom vedea în continuare că putem găsi o soluție mai eficientă.
Observația 3 Pentru o secvență de blocuri (bst, bst+1, … , bdr) aria maximă a unui dreptunghi inclus în ea va fi:
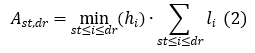
Unde am notat cu li lățimea blocului bi și hi înălțimea blocului bi.
Observația 4 Pentru o secvență de blocuri (bst, bst+1, … , bdr) există (cel puțin) un bloc bi0 cu proprietățile:
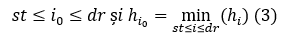
Definiție Vom numi secvență centrată în i0 (pentru i0 cuprins între 1 și n) o secvență de blocuri (bst, bst+1, … , bdr) maximală cu proprietățile (3) de mai sus.
În general spunem că o submulțime (deci și o secvență a unui șir) este maximală în raport cu o anumită proprietate (sau un set de proprietăți) dacă are acea proprietate și nu i se mai pot adăuga elemente ale mulțimii în care e inclusă astfel încât să își păstreze respectiva proprietate.

Observația 5 Dacă secvența de blocuri (bst, bst+1, … , bdr) include dreptunghiul de arie maximă asociat șirului dat și i0 are proprietățile (3), atunci secvența (bst, bst+1, … , bdr) este secvența centrată în i0.
Afirmația poate fi demonstrată prin reducere la absurd: dacă secvența (bst, bst+1, … , bdr) nu ar fi secvența centrată în i0 deși i0 are proprietățile (3), atunci aceasta ar putea fi extinsă prin adăugarea unor blocuri, obținându-se un dreptunghi de arie mai mare.
Pornind de la observația 5 deducem că rezultatul cerut poate fi obținut analizând doar secvențele centrate în fiecare bloc. Acestea sunt evident în număr de n.
Următorul pas este să calculăm cât mai eficient secvențele centrate în blocuri.
Observația 6 Pentru orice i cuprins între 1 și n secvența centrată în i este secvența de blocuri (bst[i]+1, bst[i]+1, … , bdr[i]-1) unde vectorii st și dr au aceeași semnificație ca și în aplicația 1:
și
Acești vectori pot fi construiți aplicând algoritmii prezentați anterior care au complexitatea O(n) amortizat.
Rezultatul final este:
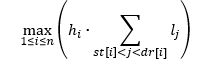
Pentru a calcula eficient expresiile de forma:
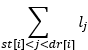
vom construi vectorul de sume parțiale asociat lui l, definit în felul următor:
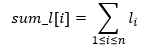
Elementele acestuia pot fi calculate rapid folosind formula de recurență:
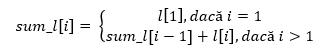
Pe baza acestuia vom putea calcula sumele lățimilor blocurilor cu ajutorul formulei:
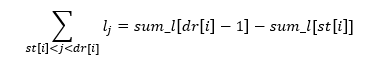
De fapt vom prefera să construim sum_l în timp ce citim datele de intrare fără a reține și lățimile blocurilor.
Programul C++ corespunzător raționamentului prezentat are 4 etape:
1. Citirea datelor și construcția vectorului de sume parțiale:

2. Construirea vectorului st:
3. Construirea vectorului dr:
4. Calculul rezultatului final:

Aplicația 3
Strategia folosită pentru problema aterioară poate fi aplicată în mod repetat pentru rezolvarea unei alte probleme clasice: determinarea submatricei de arie maximă formată exclusiv din zerouri a unei matrice binare date.
Pentru fiecare linie i a matricei vom determina ariile submatricelor maximale formate doar din zerouri care au ultima linie (linia cea mai de jos) i.
În acest scop pentru fiecare linie i vom costrui mai întâi vectorul h în funcție de valorile reținute de acesta pentru linia i-1.
Presupunând că matricea binară dată a are nl linii și nc coloane, pentru fiecare i cuprins între 1 și nl semnificația componentelor lui h va fi:
hj = numărul de zerouri consecutive din matrice aflate pe coloana j deasupra poziției (i,j)
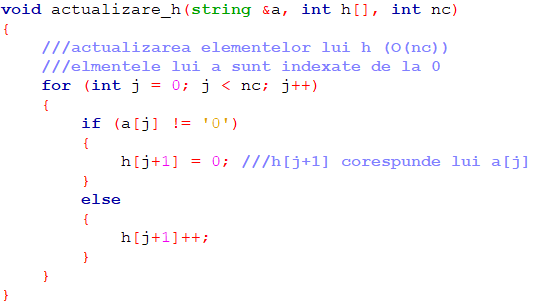
Inițial toate componentele lui h vor fi egale cu zero. Presupunând că acestea au fost calculate pentru linia i-1, elementele lui h vor fi actualizate pentru linia i conform formulei de recurență:
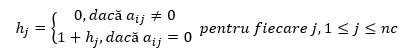
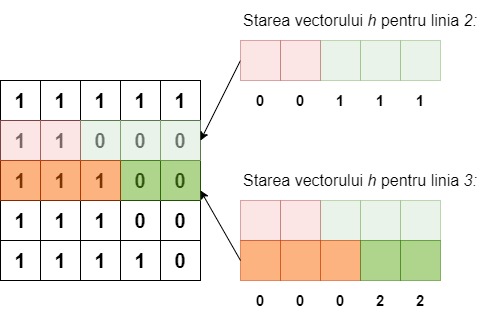
Aplicarea acestei formule de recurență face ca vectorul h să fie actualizat în nc pași pentru fiecare dintre cele nl linii ale matricei.
Odată construit vectorul h, putem aplica strategia de la problema „Skyline” determinând astfel pentru fiecare linie i a matricei submatricea de arie maximă având linia cea mai de jos i. Acest proces are complexitatea O(nc) și fiind aplicat de nl ori rezultă că întregul algoritm are complexitatea O(nl x nc) amortizat.
O ultimă observație este că în cazul problemei „Plaja” blocurile cu înălțimile calculate în vectorul h care e actualizat pentru fiecare linie au lățimea 1, nefiind necesară folosirea unui vector de sume parțiale.
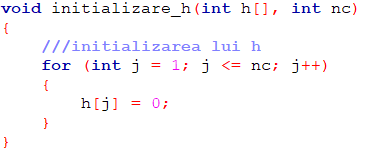
Programul C++ corespunzător ideii descrise mai sus folosește funcții corespunzătoare fiecăreia dintre cele 5 operații de complexitate O(nc). Programul principal apelează mai întâi funcția de inițializare a vectorului h, iar apoi, pentru fiecare linie i a matricei o funcție pentru actualizarea vectorului h, o funcție pentru calculul vectorului st, o alta pentru vectorul dr și în fine o funcție pentru actualizarea rezultatului general în funcție de ariile submatricelor cu ultima linie i.

Subprogramele folosite sunt:
și
